如何在Python運行長時間工作時顯示進度

在這個生成式AI、LLM的時代,藉著大模型的幫助,人們的工作產值變得更高了,特別是GPT系列,甚至不用準備資料訓練,就能得到預先訓練好模型得到的功效。
例如,假設需要將一段音訊檔案的內容整理成逐字稿,以往可能要請專業人員經過幾個小時的工作(並且花一筆錢) ,現在有了生成式的AI,或許只要呼叫api可能數秒至數分鐘就完成了,並且你會發現用AI的花費比請人來得便宜,準確度也很好,但此時如果工作的尺度再放大呢?如果你想要把之前在某次語言學習課程中的數十個甚至數百的聲音檔如mp3全部轉換成逐字稿呢?當然,Python可以做到這種重複的工作事件沒有問題,然而畢竟GPT的api呼叫,我們是把工作透過網路請遠端的LLM模型如openai的chatgpt操作,此時有可能會因為網路快慢,或者LLM的處理速度的變動,讓執行工作的狀態變得不可預期,很常發生的情形就是工作遞交出去但卻沒有在預期的時間完成,此時我們該怎麼處理呢?
當然工作可以取消掉,再從頭重新執行一次,但是雲端的api通常都是付多少用多少(pay as you go),所以我們大概不會希望如果工作只剩一點點沒做完,卻重新再讓LLM從頭跑一次的這種工作一再發生,因此如何在一個不確定時間完成的大量工作時,讓程能顯示工作的狀態是很重要的。
如果是工程師的你我,或許有非常多的方式,例如使用print印出日誌log,軌跡trace等等,這當然是OK的,但是如果控制不當,寫得太少等於沒寫,寫得太多整個畫面一直跑,很容易會變成對console的洗版而更難掌握狀態。
因此,我們可以考慮Python的生態系中的tqdm這個套件,它是一個 Python 函式庫,提供了一個快速、可擴展的進度條,適用於迴圈和所有可迭代(iterable)物件,能夠輕鬆、標準的可視化程式的執行進度。
tqdm的使用上也不會太困難,首先依照pypi.org,在pip or pip3安裝tqdm,如果順利應該看到如下:

此時假設有個工作,其中迴圈要跑100次,裡面的函數會耗時0.1秒,我們可以用sleep取代其真實工作做示意時, 與其用print()一行一行的顯示log說明現在執行的情形,可以用tqdm來顯示如下圖:
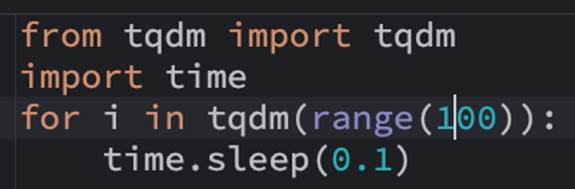
沒錯,它很簡單,只是在range的外面再套用一個tqdm的函數即可,此時可以看到進度條在console的顯示如下:

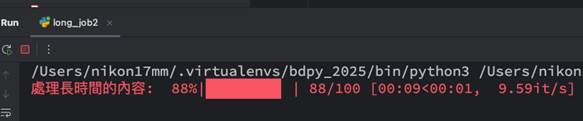
分別是百分比、進度條顯示的百分比、目前迭代個數除以所有個數、運行時間,以及每秒執行了多少迭代等等,所以對於目前進度可以有更具體並且精簡的概念。
然而程式不見得只有一個需要注意目前運行進度的地方,有時程式可能會分好幾個階段,而每個階段都需要有長時間運行的監控能力。
例如我們想要把好幾個影片先擷取聲音的部份另存檔案,再把這些聲音都逐一聽寫 轉成文字檔案,或許再把這些文字批次翻譯轉成其它語言,此時可以在呼叫tqdm中加上描述於desc參數如下:
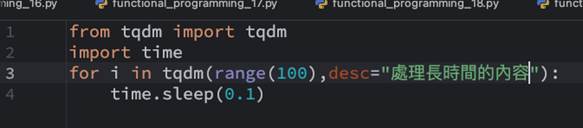
此時看到的結果會是在百分比前面出現desc提示的字句如下:
tqdm非常彈性,要顯示進度不必在迴圈的for i...之中,如果一個函數會yield數值,每次呼叫也可以趨動tqdm的進度,例如下圖,tqdm會呼叫一個函數,該函數會yield一個結果:
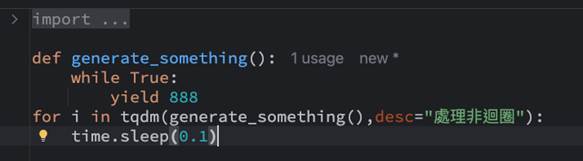
此時檢視的結果會顯示目前執行了多少次迭代如下,並且也會有一秒幾次迭代的統計:
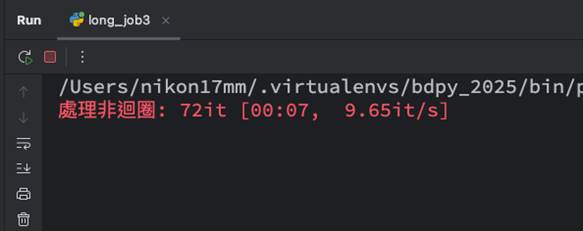
雖然使用yield沒有迴圈的上限(或者至少在執行tqdm時不知道上限),所以tqdm不知道如何做出百分比(但會告知目前的狀態),但我們可以給它一個預期會執行的數量並且送進tqdm的total參數:
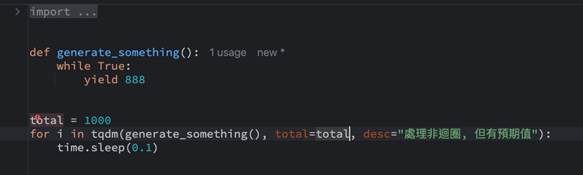
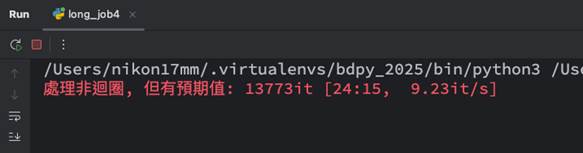
此時執行後,一樣可以看到進度bar,因為會有預期值了,跟著目前迭代的個數就可以產生截至目前的比例:

並且由於yield還是會持續執行,在沒有tqdm時程式是會繼續執行的,所以就算套用了tqdm,Python行為不變,超過時依然在tqdm的顯示會持續顯示改變:
如果想要讓UI更友善,當有許多需要留意的進度需要表現,此時可以增加不同的顏色如下,定義在一個陣列之中,再傳入colour的參數裡:
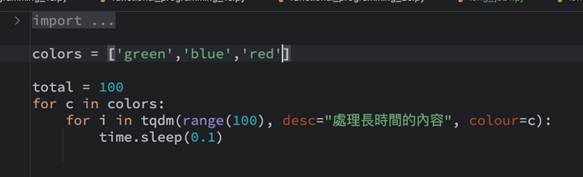
此時看到的結果如下,每一個process會顯示不一樣的內容:

除了在本文中介紹的內容之外,tqdm當然有更多的功能,您可以查看官方文件來取得更完整的介紹。
同時tqdm對於Python資料處理library、pandas也有很不錯的整合,所以不管在資料處理、機器學習、深度學習甚至是大語言模型應用,不管本地或遠端,tqdm都可以找到蠻多適合運用的場景喔。
您可在下列課程中了解更多技巧喔!






0 意見:
張貼留言